White Paper
Ho Jin Yu*, Sanio Jung*, Emmett Kim
May 7, 2025
Introduction
Neural networks have passed countless Turing tests, but face-to-face conversation remains the final challenge. Even though state-of-the-art video models have made incredible breakthroughs [1][2], the lack of human interaction in datasets leads the model to be a good painter, but not a good communicator. To make AI truly serve humanity, mastering human conversation is mandatory. We need a new approach.
Considering typical talking head video models are trained on roughly thousands of hours of speech data [3][4], building an architecture capable of training at a million-hour scale is our radical leap forward. This includes challenges like achieving end-to-end latency below 400 ms, the threshold for human conversational turnaround. Pickle is at the forefront of this development as the first company pursuing both real-time performance and context understanding of large-scale video models. To enable conversational data availability at a scale never attempted before, we have built our own growing data source.
What is an Interactive Avatar?
An Interactive Avatar is an AI Avatar indistinguishable from a human in face-to-face conversation. Yet such conversations are far more complex than intuition suggests. Picture how differently you speak to your mother and to your manager. Teaching that level of context awareness to an AI avatar is what turns
looks human into feels human.
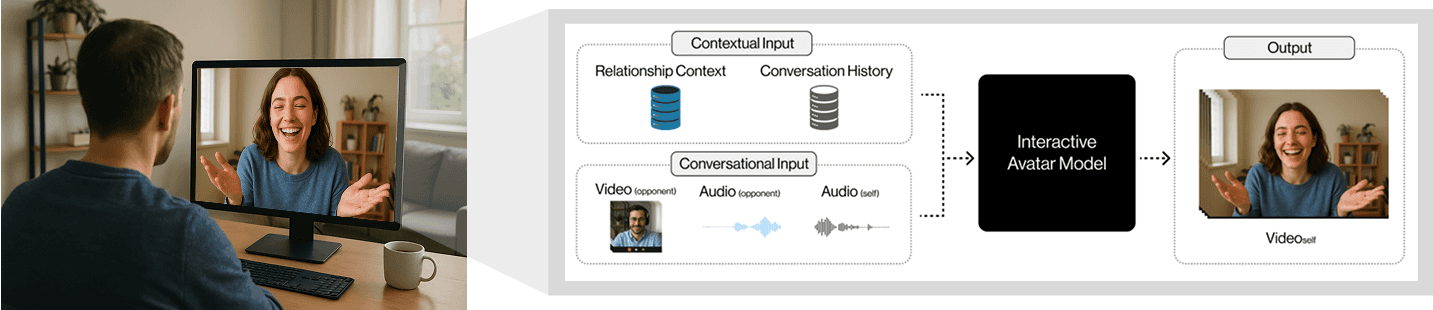
Figure 1. How Interactive Avatar Model works
To create this Interactive Avatar, we can break down the most critical technical challenges into two main categories:
1. Teaching the model Interactive Intelligence, which understands conversational context.
2. Ensuring frame generation speed of the model > 25 fps with latency < 400 ms.
According to the 7-38-55 rule [5], words carry only 7 % of conversational meaning; the remaining 93 % lies in vocal nuance (38 %) and body language (55 %). These minor shifts in tone, expression, or posture are terribly difficult for machines to learn. An Interactive Avatar must detect such non-verbal cues and respond with matching vibe. Photorealism alone is not enough—the real benchmark is Interactive Intelligence.
Also, no matter how intelligent a model is, a study in cognitive psychology [6] suggests that it will not feel interactive enough without achieving a generation speed (model inference) above 25 fps and latency below 400 ms, due to the lack of real-time awareness.
Interactive Intelligence via Scaling-Up Conversational Data
Traditional Interactive Avatar pipelines isolate perception from rendering—treating conversation as a sequence of “listen, then speak” relay [7][8]. Even though this modular split makes engineering simple, it discards cross-modal cues at the boundary and leaves only a lossy summary for each module. Because signals are unrecoverable, the two-stage system cannot, even in principle, reproduce the full joint distribution of human interaction.

Figure 2. Traditional approach VS End-to-End Streaming approach
To enable truly human-like interactions, the model must be trained end-to-end, with the conversational data. Conversational data is defined as collections of dialogue sessions involving two or more participants. Each session should comprise the text describing relational context between participants, and the video/audio from each participant.
Because end-to-end training objective is more complex than the traditional “listen, then speak” approach, we need a lot more data. With roughly 10 million hours of conversational data, the model can learn human interaction in an end-to-end manner. And there’s already a huge natural source where we can drain limitless conversational data: video calls.
Current video call platforms collectively have around 650 million DAU, and average usage per user is 52 minutes per day [9]. Therefore, capturing only 0.1% of them is enough to accumulate the targeted 10 million hours of data in just two weeks.
How Pickle get conversational data

Figure 3. Pickle’s technical architecture
Data collecting pipeline
①
Video for Personal Model Training:
5 hours of human talking videos are collected daily.
②
Conversational Data for Foundation Model Training:
60 hours of conversational data are collected daily.
Training pipeline
①
LoRA Training [10] for Personal Models:
Three foundation models are personalized by LoRA training with user’s talking video.
②
Large Scale Training for Foundation Models:
DiT foundation model is trained with large-scale conversational data, unfreezing Context Projector, Cross-Attention Layer of DiT Blocks.
Inference pipeline
Renderer type
● : NeRF
● : DiT (in developing)
①
②
Extracting Audio Feature:
Wav2Vec [13] Model extracts audio features from the specific amount of chunk at the most recent audio buffer.
③
Generating Landmark Sequences:
Motion Renderer takes audio features as input and generates a landmark sequence. Past landmarks and audio are used for ensuring continuity.
④
Rendering Frames with NeRF [14]:
NeRF renders video frames conditioned on landmark sequences. The frames are then sent to the Pickle Camera which can be selected on video call apps.
①
②
Extracting Context Feature:
Context Projector(pre-trained upon Wav2Vec and multi-modal LLM layers) extract context features from video/audio of current call.
③
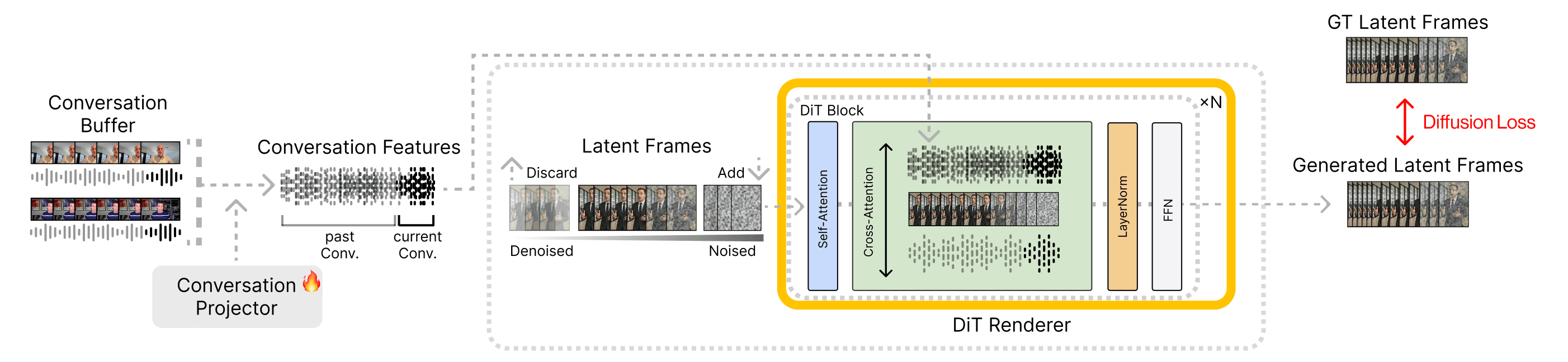
Rendering frames with DiT:
DiT Blocks denoise latent frame buffer using audio features and context features. To generate video frames faster with continuity, the middle part of frames buffer which is denoised enough, are decoded by 3D VAE and sent to the Pickle Camera.
Data draining & Training pipeline
Each month, 2,500 Pickle users generate about 1,800 hours of conversational data and 150 hours of single-speaker talking video. Whereas roughly 70 percent of typical public datasets are discarded as low quality, nearly all of our data is usable and far denser because every conversation can be split into individual speaker tracks with perfectly aligned audio and video.
Conversational data is used first for training the DiT-based foundation model and later for the personal model. The goal of each stage is to teach the model general and individual patterns of human interaction. During training, the Conversation Projector learns to extract conversational features, while the Cross-Attention layer learns how to apply them when rendering video frames.
Under 400ms towards seamless communication
The latency of an Interactive Avatar can be split into three parts. Network latency, chunking latency, and model inference latency. Network latency is caused by the communication between the client and the server. And stream chunking latency occurs because the models require sufficiently long inputs to generate smooth, continuous video frames. Last, model inference time is directly added to the latency of rendering each frame.
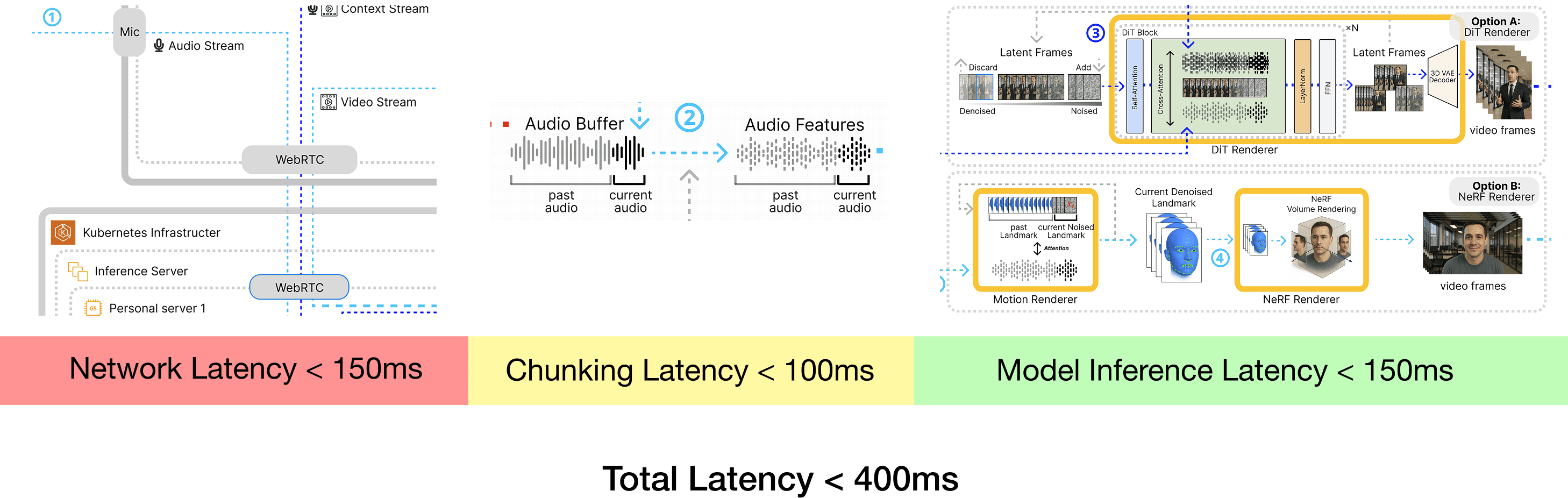
Figure 5. Latency requirements
Since network latency is 150ms total in the worst case and cannot be reduced, we should reduce chunking latency and model inference to under 250ms to ensure 400ms total. For the chunking latency, we fine-tuned feature extractors and rendering models to operate on chunk size < 100ms, which is 5x faster than the original.
To reduce model inference latency, we have applied FP8 TensorRT quantization [17] and model pruning [18] to reduce the amount of computation by 8x. Also, model-specific acceleration has been applied to each models. For the NeRF renderer, tri-plane NeRF projects 3D space onto three 2D planes [19] and achieves 30 ms on L40S GPU. For the DiT renderer, Flash Attention [20] and timestep distillation [21] can reduce inference latency by 50x. However, the DiT renderer remains the bottleneck at ~800 ms input-to-frame latency, so reducing it below 150 ms is now a primary research focus.
Conclusion
Making Interactive Avatars indistinguishable from a human represents one of the most ambitious frontiers in AI, intersecting three critical developments: world’s first conversational data scaling, advancements in scalable neural network architectures, and breakthroughs in ultra-low latency inference technologies. Pickle is uniquely positioned as a consumer company to achieve human-indistinguishable interactive avatars through unique data acquisition flywheel and a commitment to sub-400ms inference latency.
Pickle’s approach, leveraging millions of hours of conversational data combined with end-to-end training methodologies, is not only feasible but essential. By utilizing current video call ecosystems and continuously refining state-of-the-art architectures like DiT, Pickle is pioneering a future where technology genuinely enhances human connectivity.
References
[1] Sora: Creating Video from Text. 2025. https://openai.com/index/sora/
[2] Movie Gen: A Cast of Media Foundation Models. arXiv 2410.13720, 2024. https://arxiv.org/abs/2410.13720
[3] OmniHuman-1: Rethinking the Scaling-Up of One-Stage Human Animation. arXiv 2502.01061, 2025. https://arxiv.org/abs/2502.01061
[4] MoCha: Towards Movie-Grade Talking Character Synthesis. arXiv 2503.23307, 2025. https://arxiv.org/abs/2503.23307
[5] https://en.wikipedia.org/wiki/Albert_Mehrabian
[6] Video Increases the Perception of Naturalness During Remote Interactions with Latency, 2012. https://dl.acm.org/doi/10.1145/2212776.2223750
[8] AgentAvatar: Disentangling Planning, Driving and Rendering for Photorealistic Avatar Agents, 2023. https://arxiv.org/abs/2311.17465
[9] https://www.zoom.com/en/blog/how-you-used-zoom-2022/
[10] LoRA: Low-Rank Adaptation of Large Language Models, 2021. https://arxiv.org/abs/2106.09685
[11] https://kubernetes.io/docs/concepts/overview/
[12] https://webrtc.org/
[13] wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations, 2020. https://arxiv.org/abs/2006.11477
[14] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, 2020. https://arxiv.org/abs/2003.08934
[15] https://developers.zoom.us/blog/realtime-media-streams/
[16] https://developer.apple.com/documentation/coreaudio/capturing-system-audio-with-core-audio-taps
[17] https://developer.nvidia.com/tensorrt
[18] https://pytorch.org/tutorials/intermediate/pruning_tutorial.html
[19] Efficient Geometry-aware 3D Generative Adversarial Networks, 2021. https://arxiv.org/abs/2112.07945
[20] FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision, 2024. https://arxiv.org/abs/2407.08608
[21] Diffusion Adversarial Post-Training for One-Step Video Generation, 2025. https://arxiv.org/abs/2501.08316
Appendix
Appendix A: AI avatar model landscape
AI Avatar models are composed of two distinct types of models: rendering models that produce videos reflecting the user's appearance and movements, and feature extracting models that extract features from the user's voice and text prompts. For the feature extracting models, pre-trained models such as Wav2vec for audio and the T5 Encoder for text are widely used.
Architectures for the rendering models can be categorized into 3 types. Diffusion Transformer (DiT), Neural Radiance Fields (NeRF), and 3D Gaussian Splatting (3DGS).

Table 1. Comparison between DiT, NeRF, 3DGS
SOTA DiT-based models require pre-training with O(1M) hours of general image/video data. They offer the highest diversity but take 40-500 seconds to generate a 5-second video, sometimes resulting in unstable outputs. Conversely, NeRF and 3DGS-based models utilize 3D prior for effective training, focusing on learning each object’s 3D distribution. Thus NeRF and 3DGS need more additional training for each object, and exhibit limited diversity depending on the object used in training. But, they reliably produce stable outputs and achieve real-time rendering speed.
In short, NeRF/3DGS-based approaches are adopted for stable, real-time streaming environments (e.g., video calls), while a DiT-based approach, slower yet richer in diversity, is utilized for non-real-time environments. Active work—including Pickle’s—is pushing DiT toward real-time performance, with only a few key breakthroughs remaining.
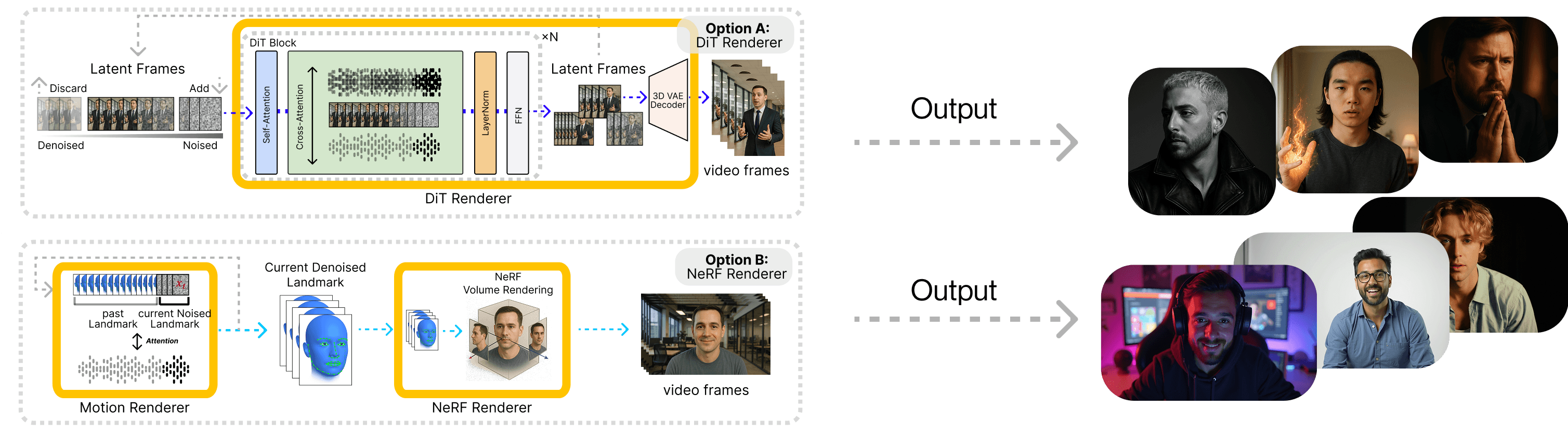
Figure 6. Architecture & output of DiT, NeRF, 3DGS
Appendix B: Personalization training
Generating a personalized AI Avatar, which means personalizing DiT, NeRF, and 3DGS models for one person, can be achieved by additional Low-Rank Adaptation(LoRA) training with one-person talking video. In LoRA training, new layers are inserted only at the highest-capacity parts of each core model with the base weights frozen, so the avatar can absorb a specific person’s features without compromising the model’s original performance.
After the LoRA training, rendering models capture fine details such as mouth structure, skin tone, body shape, and hair, ensuring that the avatar’s appearance stays stable and consistent even during long video sessions. The models can also learn user-specific gestures, lip movements, and facial expressions, bringing the avatar’s motions much closer to the user’s own.

Figure 7. Personalizing by LoRA training with physical contexts
© Pickle, Inc. May 2025, White Paper: Scaling Laws for Interactive AI Avatar